持续学习
基本介绍
持续学习任务能够在模型训练后接收新的训练数据,更新模型来提升在新数据上的性能,并尽可能减少对旧数据性能的影响。与简单地使用所有数据重新训练一个全新模型不同,平台基于持续机器学习技术构建,旨在解决由于数据变化引起的概念漂移、灾难性遗忘、分布外问题等,而无需任何编码和用户的机器学习专业知识。
使用方法
准备数据
目前,平台支持以csv格式输入的结构化数据文件,并且使用逗号作为分隔符并包含表头。
与此同时,由于持续学习任务需要不断的接受新的数据,目前在数据集中建议包含具有时间属性的字段用于描述这条数据的时效性,例如:“2023/6/1 0:15”、“2024-12-31 00:00:05”等格式。
在其他版本(如私有部署)中,存在多种数据输入形式,这些形式可以与我们的专用数据存储结合使用,以增强吞吐量性能。未来发布的版本中将提供更多的数据形式支持。
任务配置
登录平台后,点击页面右上角的新建持续学习按钮,将弹出新建任务对话框。
选择获取训练集方式下拉选项为“手动上传”,用户只需要将数据集拖拽到文件对话框,点击下一步完成文件上传。
目前获取训练集方式只支持“手动上传”。在其他版本(如私有部署)中,将支持更多获取训练集方式,如:文件服务器模式、结构化数据库等。
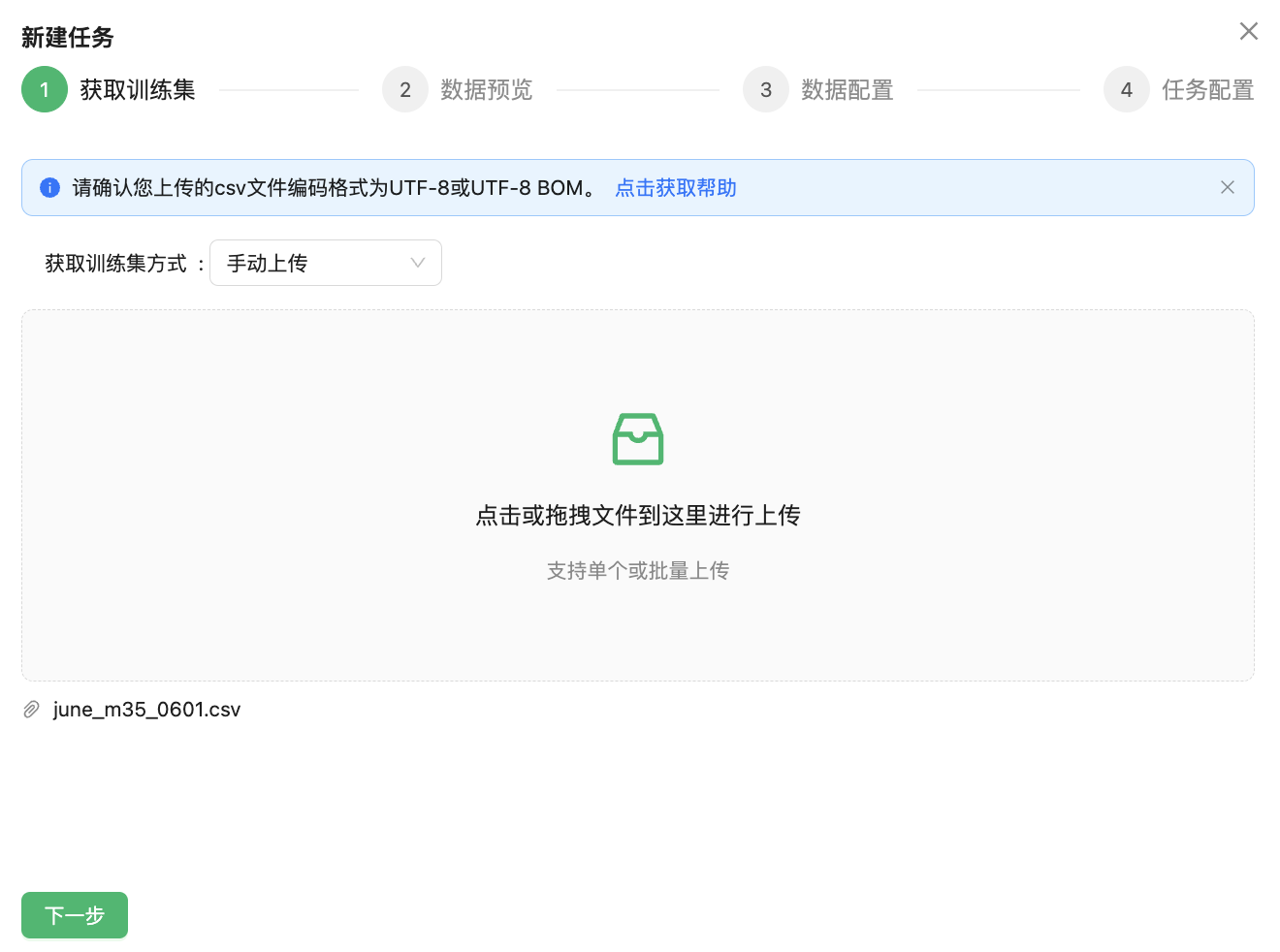
点击下一步完成上传数据预览。
继续单击下一步,平台将自动解析文件中每个字段的类型。用户需要确认以下信息:
⊖ 确认需要预测的字段,并从相应的字段下拉列表中选择“标签”。默认设置为“特征”。
⊖ 确认数据集中不需要的字段,然后从相应的字段下拉列表中选择“忽略”。
⊖ 确认字�段中的非数值类别特征字段,并将“是否类别特征”开关设置为启用。
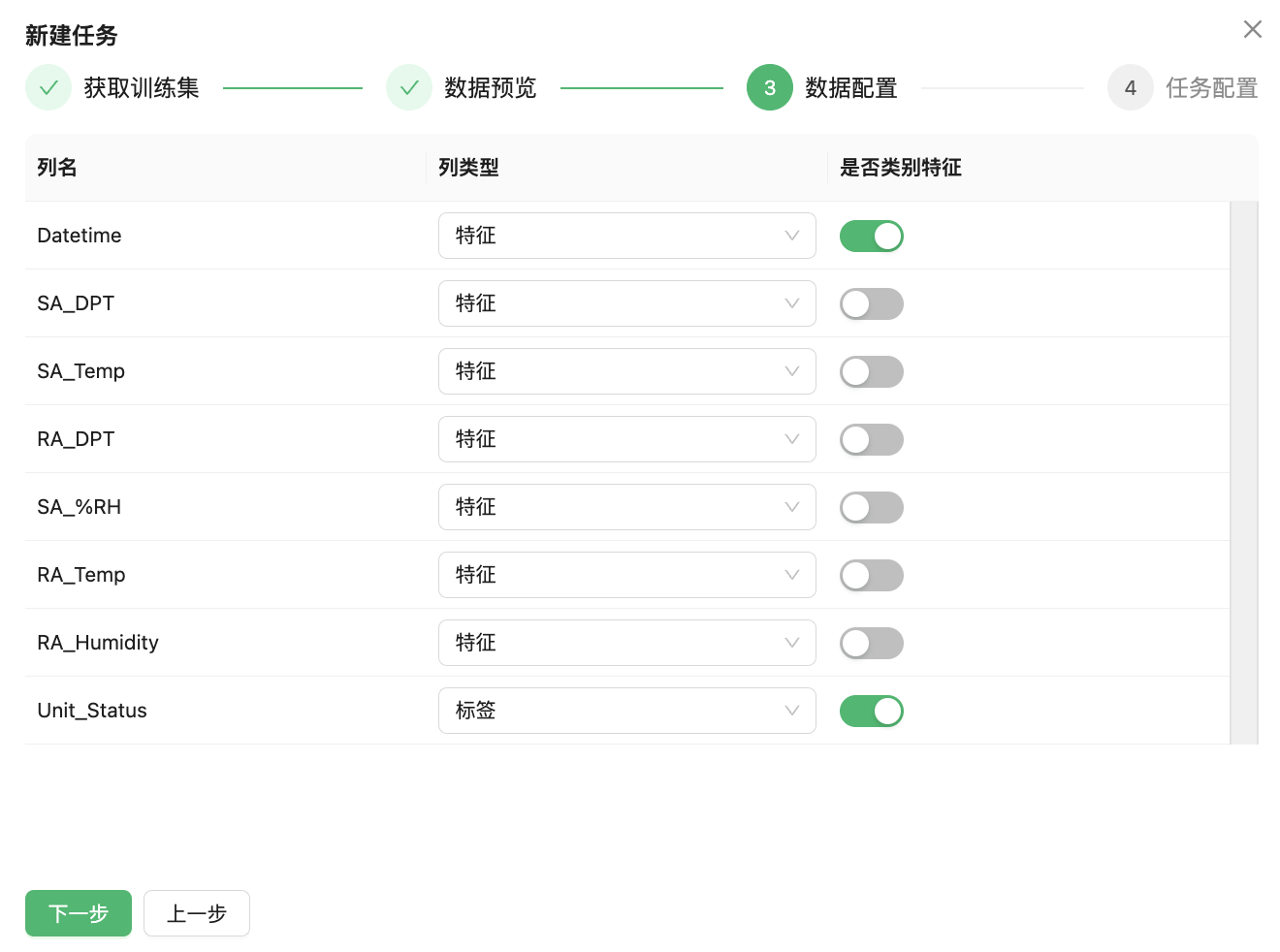
需要注意的是,与自动化机器学习任务所不同的是持续学习任务需要配置“时间列索引”或者“时间组标识”用于标记数据集中的具有数据属性的字段。
例如数据集中的时间字段为“Datetime”,选择该字段为“时间列标识”点击“配置”按钮完成时间字段配置。
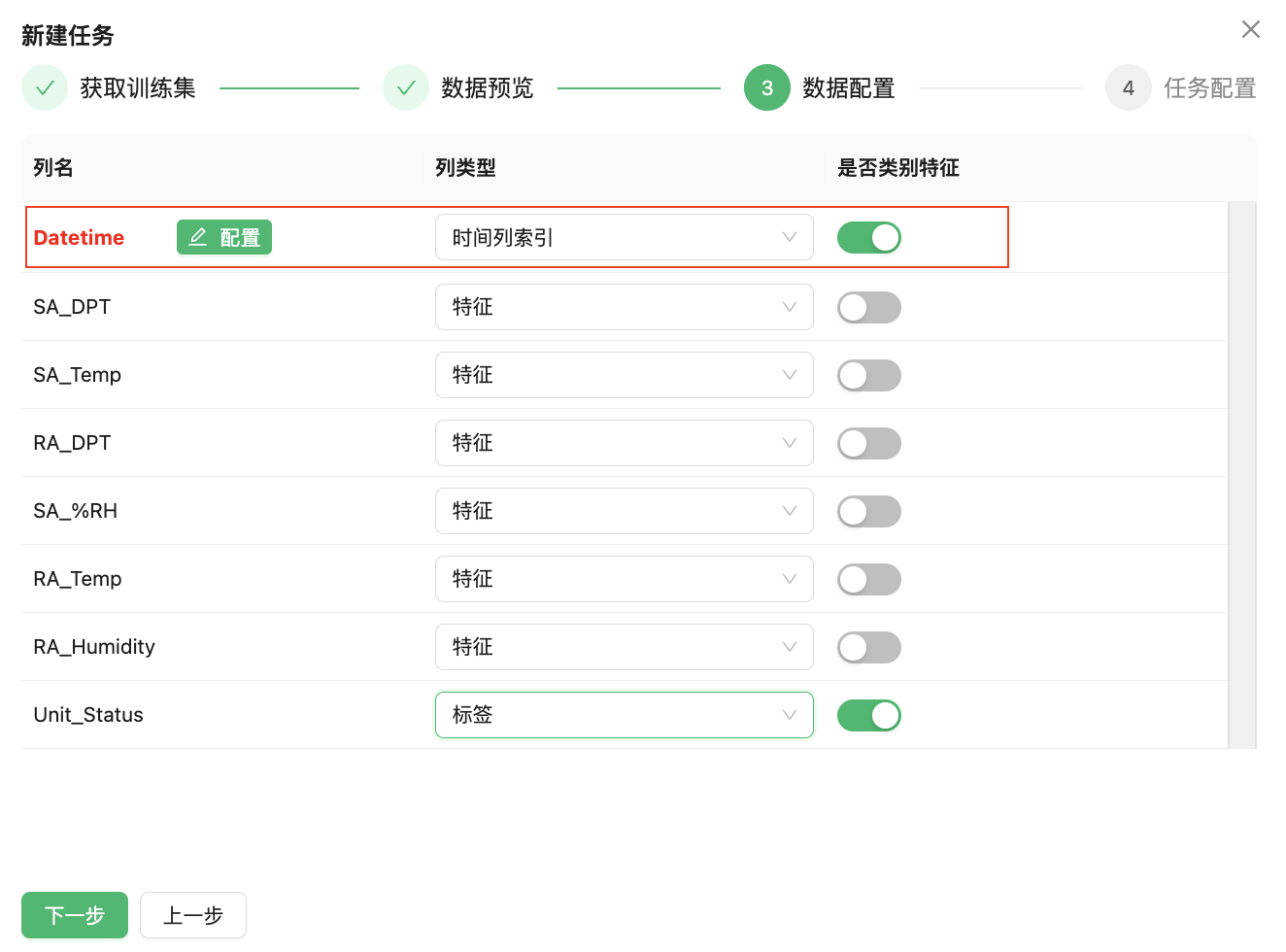
需要注意的是,用户可以选择时间字段仅仅是用于标明数据新旧,系统将不启用时序算法,同时将跳过时间字段配置的相关选项;如果用户需要启用时序算法,则需要配置时间字段相关选项。

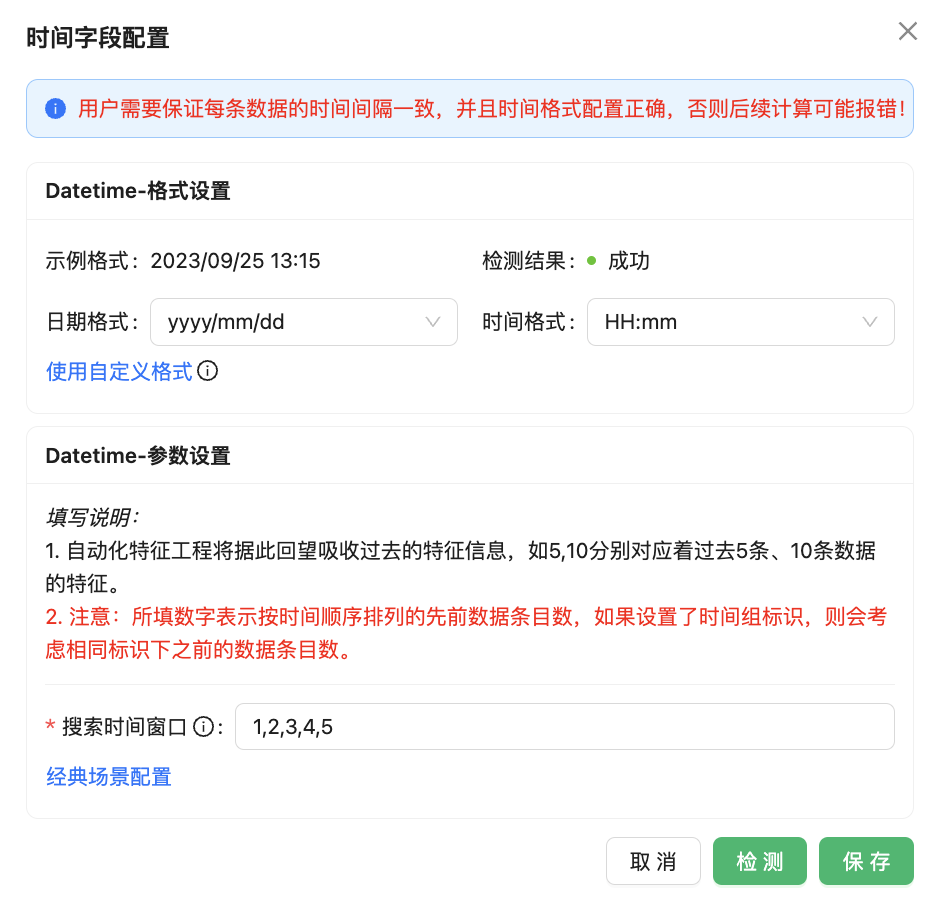
在“时间字段配置”对话框中主要配置时间字段的“格式设置”和“参数设置”。
⊖ 格式设置:用于设置数据集中时间字段的具体格��式,例如:字段“Datetime”的格式为“2022/6/1 0:20”,则需要选择符合数据格式的选项,这里选择“日期格式”为“yyyy/mm/dd”,“时间格式”为“HH:mm”。
⊖ 参数设置:由于自动化特征工程将根据该配置回望过去的特征信息,此时根据当前任务的实际需求和业务场景进行“搜索时间窗口”的配置。
配置完成之后可以点击“检测”按钮进行自动检测,当“检测结果”为“成功”则完成时间字段配置。
单击下一步设置任务名称、AutoFE尝试次数、AutoML尝试时间预算、备注等信息,然后单击确认完成任务创建。
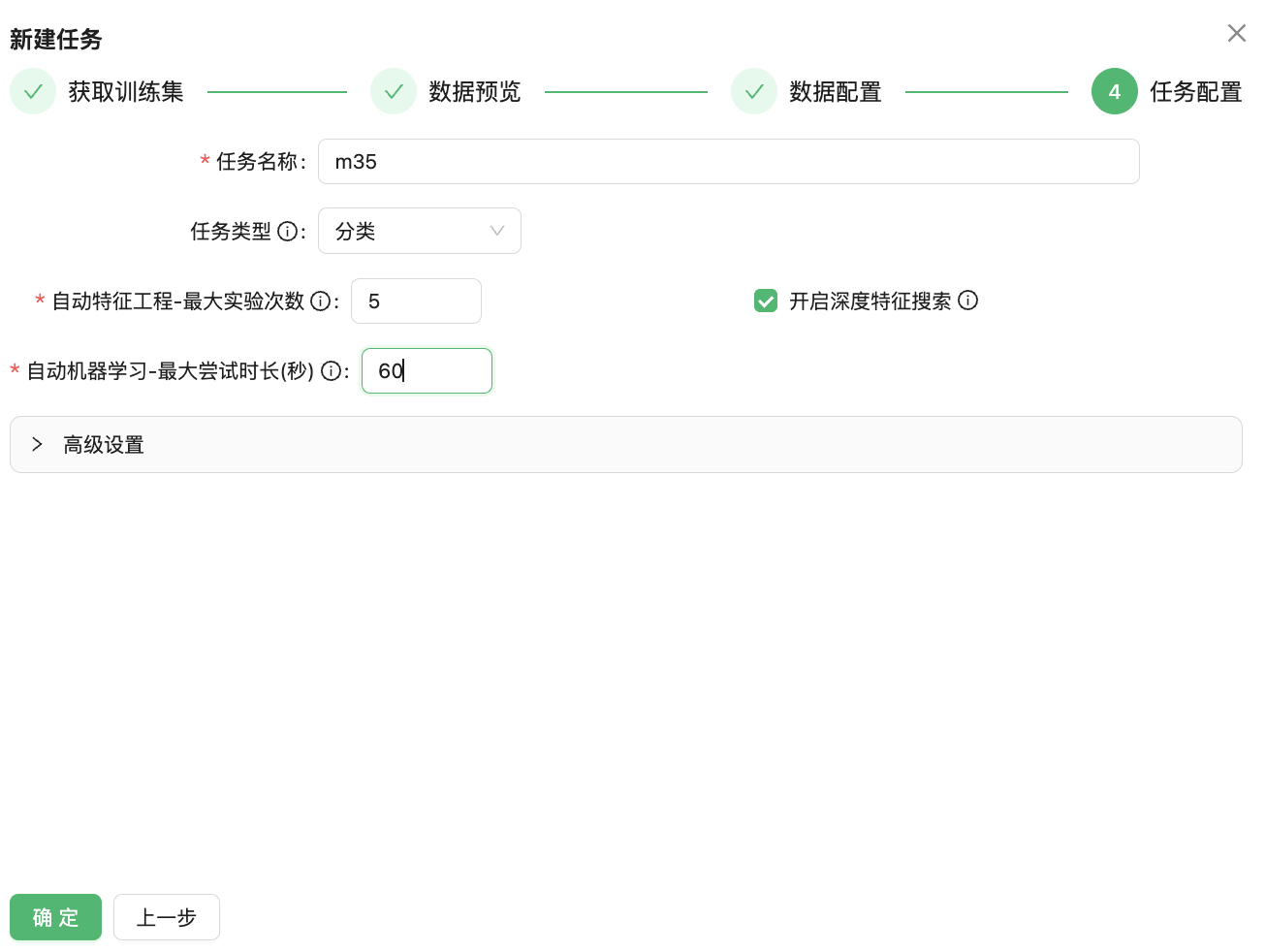
任务类型下拉选项提供了两种机器学习任务类型的选择:分类和回归。如果标签是类别特征,则是分类问题;如果标签是数字,那么这是一个回归问题。在这种情况下,选择分类。
完成任务配置后,在自动化持续学习任务列表中查看创建的任务。

模型训练
在任务列表中选择已创建的任务,然后单击“运行��”进行确认。整个建模过程完全自动化。

如果任务状态为“正在运行”,则训练任务正在运行。

当前批次运行完成后,将显示当前模型训练的最佳精度。此训练的最佳准确度约为0.99。

需要注意的是,与自动化机器学习任务所不同的是持续学习任务会一直持续的运行。每当探测到新的数据到来之后,将会在此前训练的基础之上触发新一轮的模型训练。每触发新一轮的模型训练将会生成新的模型版本,一旦没有新的数据到来,则会等待新数据到来再次触发模型训练。
当时任务状态为“探测中”表示上一轮模型训练完毕并且等待新数据的到来。用户可以点击“追加数据集”按钮继续上传数据集,此时将新的数据提供当前模型进行新一轮的训练,点击“确认上传”按钮等待触发新的模型训练。

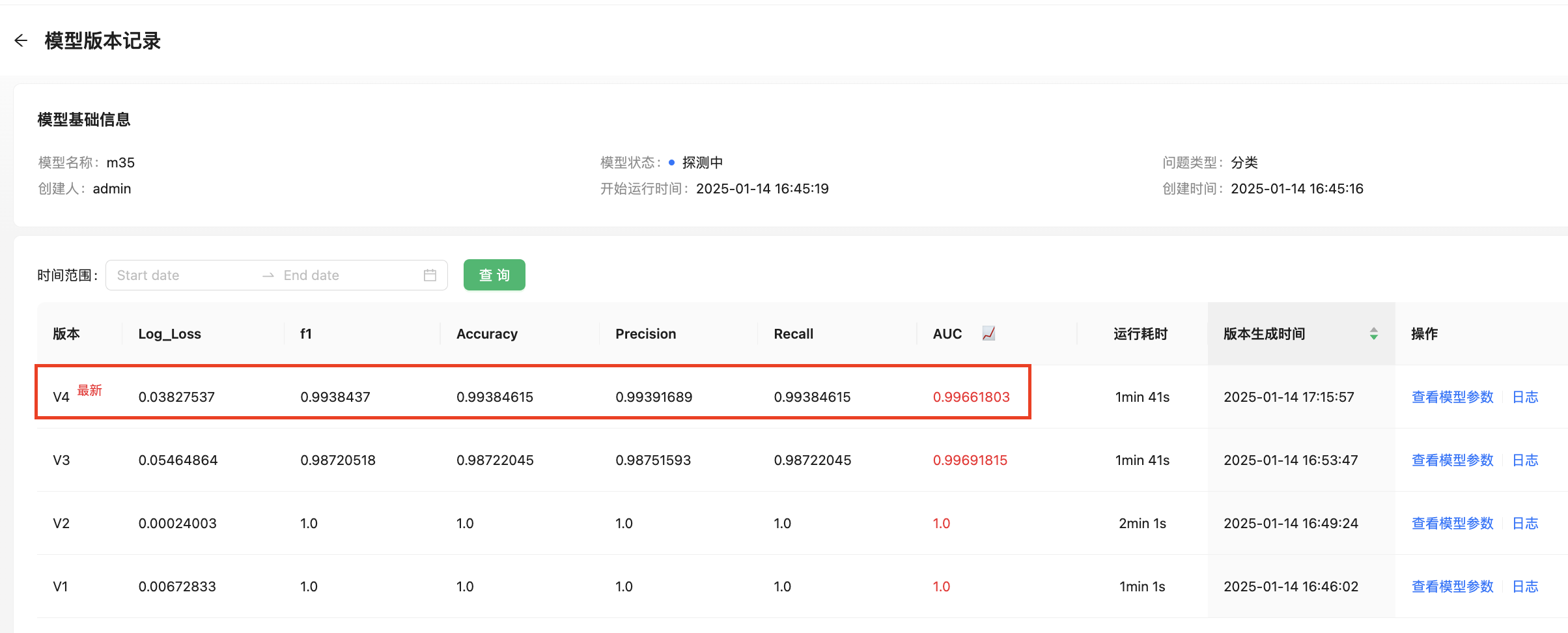
随着时间的推移,模型可能在不同的时间点探测到新的数据,这会生成不同的历史版本。用户可以点击“模型版本”查看模型版本详情。

在模型版本详情中可以看到每次触发模型训练的历史记录,涉及:模型版本号、模型触发时间、模型评估指标,训练耗时等信息。用户可以点击具体模型版本的“模型参数”查看历史版本更加详尽的信息。
模型查看
用户可以点击“更多”中的“查看模型参数”查看最新模型版本的具体信息。
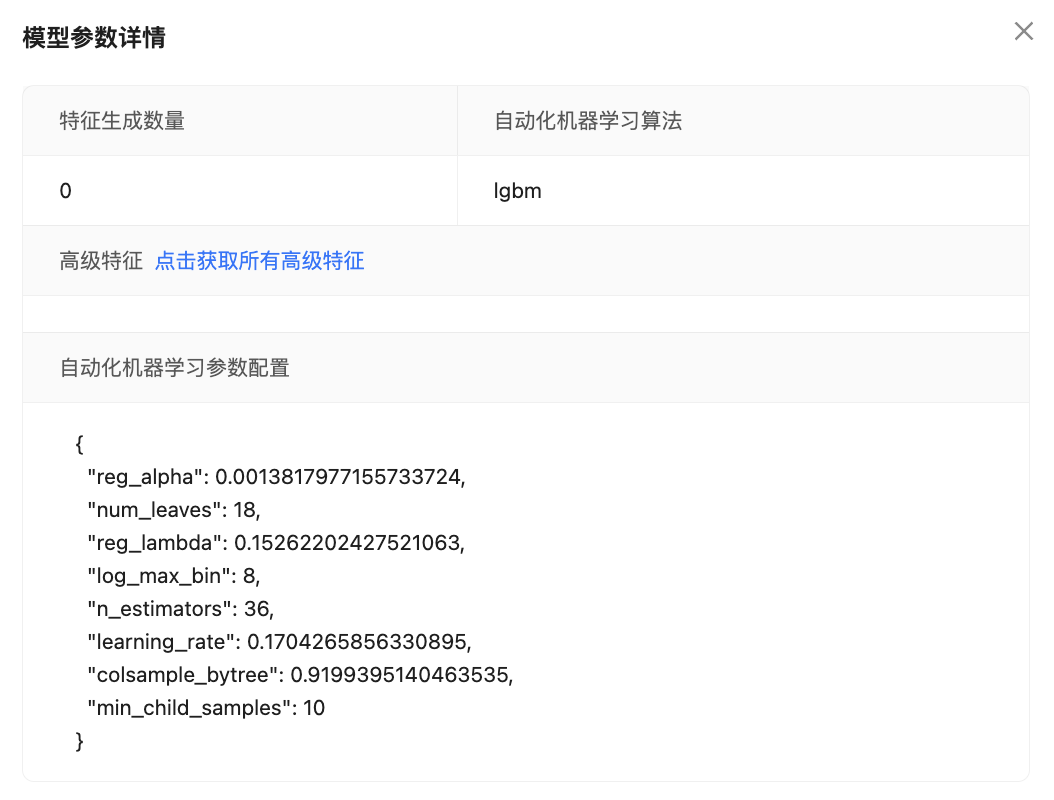
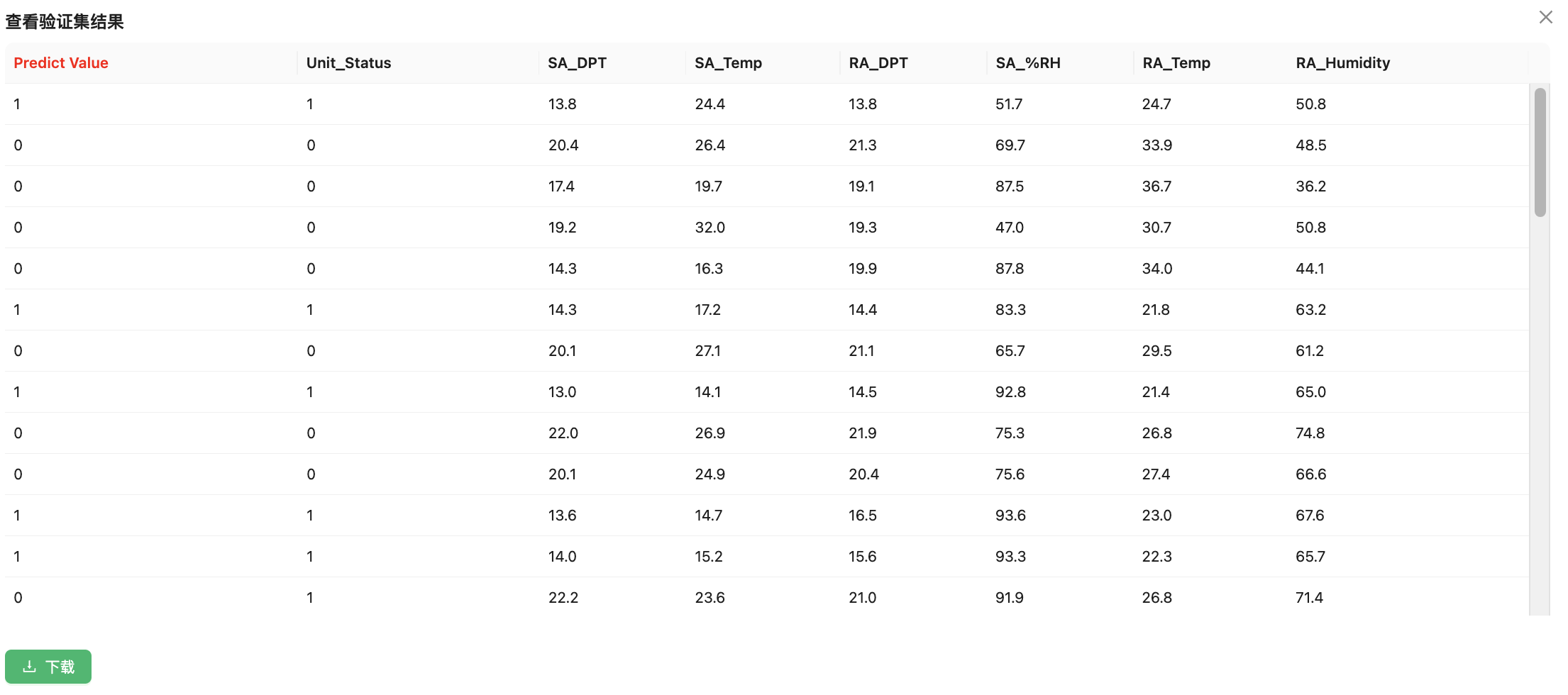
用户可以点击验证集结果查看该模型对上传数据文件中的数据所预测的结果。
模型预测
在建模任务列表选择对应任务点击预测可以进行模型预测。此时可以将需要预测的数据文件上传到平台,这里对上传数据文件的要求和准备数据环节是数据文件要求是一致的。
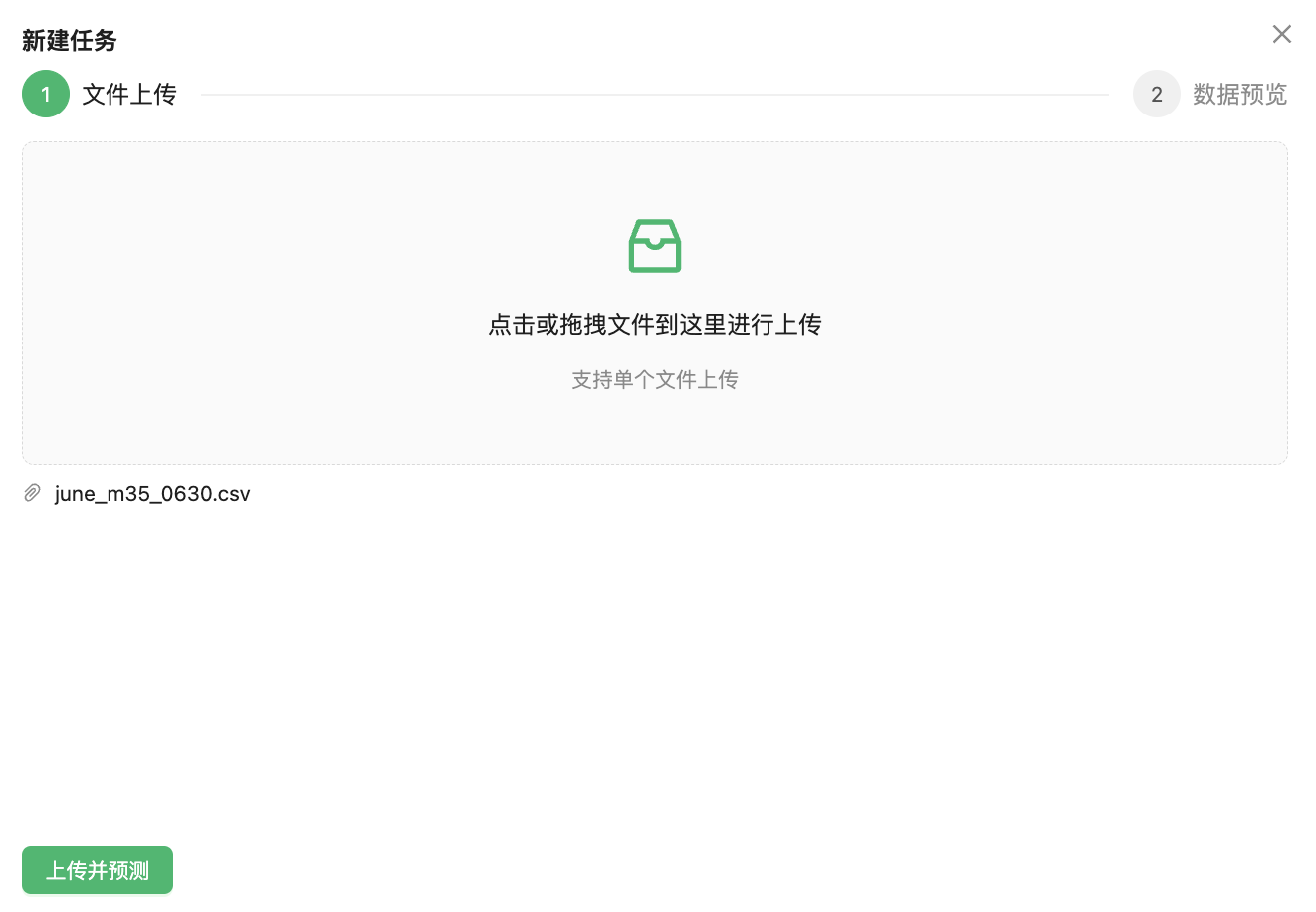
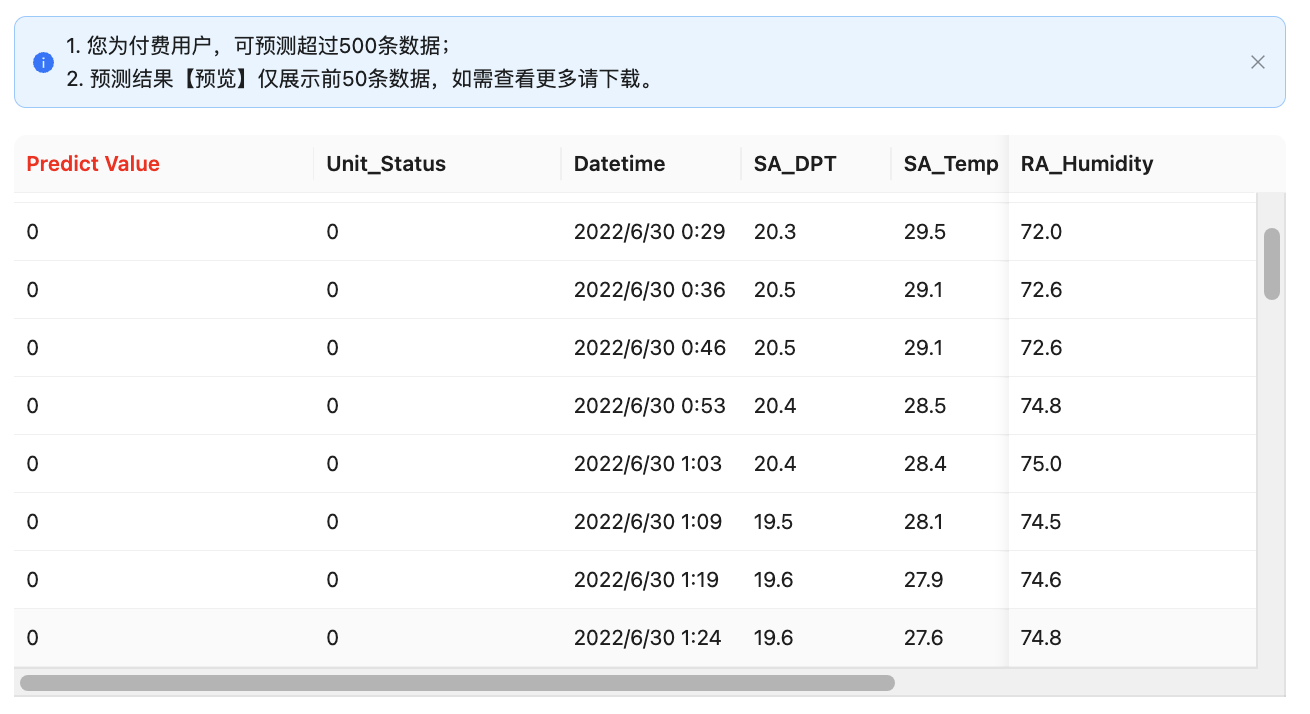
点击上传并预测,稍等片刻在数据预览中所展示的数据则是通过训练好的模型所预测的结果。
红色高亮表示的“Predict Value”这一列为模型预测的结果,同时提供下载功能将预测结果下载到本地。