模型报告
如何获取模型报告?
本平台不仅可以将训练完成的模型下载下来进行后续的机器学习工作,还可以通过可视化的方式更加直观的展示当前模型的相关重要信息,这对机器学习模型的研究提供了重要依据。
用户可以在建模列表中对应的建模任务中点击下载报告即可获取模型报告,如下图:

下载之后可以获取到一个名称为 report_*.zip 压缩文件,通过解压工具解压之后即可获取模型报告内容。
模型报告下载示例可参考:《附录-2:模型报告示例》
模型报告解读
本平台会自动为用户生成压缩之后的模型报告,解压缩之后的内容大致如下:

其中包括了原始图片文件夹、以及不同格式的报告文件(支持Word,PDF和Markdown)。
本平台提供的报告包括了训练数据的特征空间分布、模型可视化、验证数据的各类指标三个方面。
下面我们会通过一个分类任务的模型报告为大家如何查阅报告中的相关内容。
一、特征空间分布
高级特征是从不同的方向更深入地解释数据。下面使用的几种描述特征指标的手段不能衡量出特征表达能力的全部维度,特征彼此之间并不是替代关系,拥有同等的重要性。
特征空间分布可以简单分为两个方面,可以简单地分为训练前和后。训练前,通过特征��空间的分布,从而去选择合适的特征和模型 进行训练。例如可以通过大部分特征是否有线性关系去选择模型。训练后,如果使用的是树模型的话,我们将得到每个特征的贡献值,可以通过这个贡献程度来反复调整我们训练的模型,也可以通过特征重要性来体现生成特征的有效性。
出于报告篇幅和简洁性的考虑,我们这里只对处理过后的数据进行分析,并只输出部分数据的。
如需要对原始数据或者编码分析,那么可以使用ChangTianML工具进行分析。
1. 训练前的数据分析
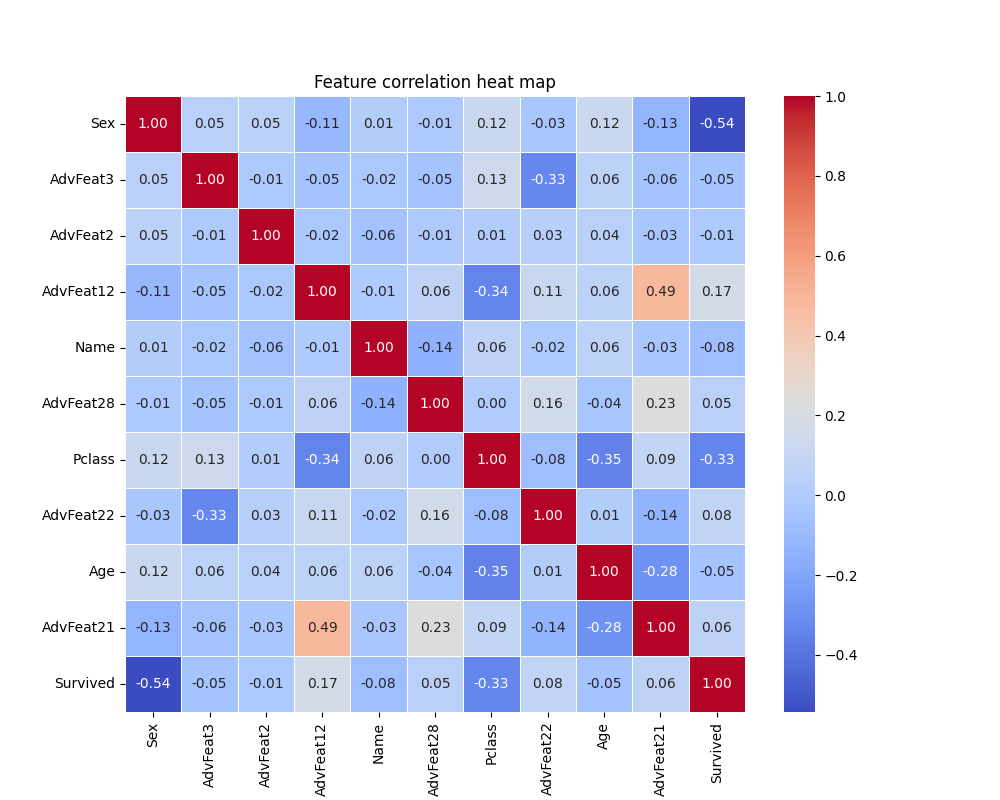
1.1 热力图 (Heat Map)
热力图表示的是特征之间的相关性。这里展示的是模型特征重要性前10的特征与标签的相关性。
这里计算的相关系数是皮尔逊相关系数(Pearson correlation coefficient),其公式如下:
皮尔逊相关系数衡量了两�个变量之间的线性相关性,其取值范围为-1到1。具体而言:
- 1表示完全正相关,即:一个变量增加,另一个变量也以相等的比例增加。
- 0表示无相关性,即:两个变量之间没有线性关系。
- -1表示完全负相关,即:一个变量增加,另一个变量以相等的比例减少。
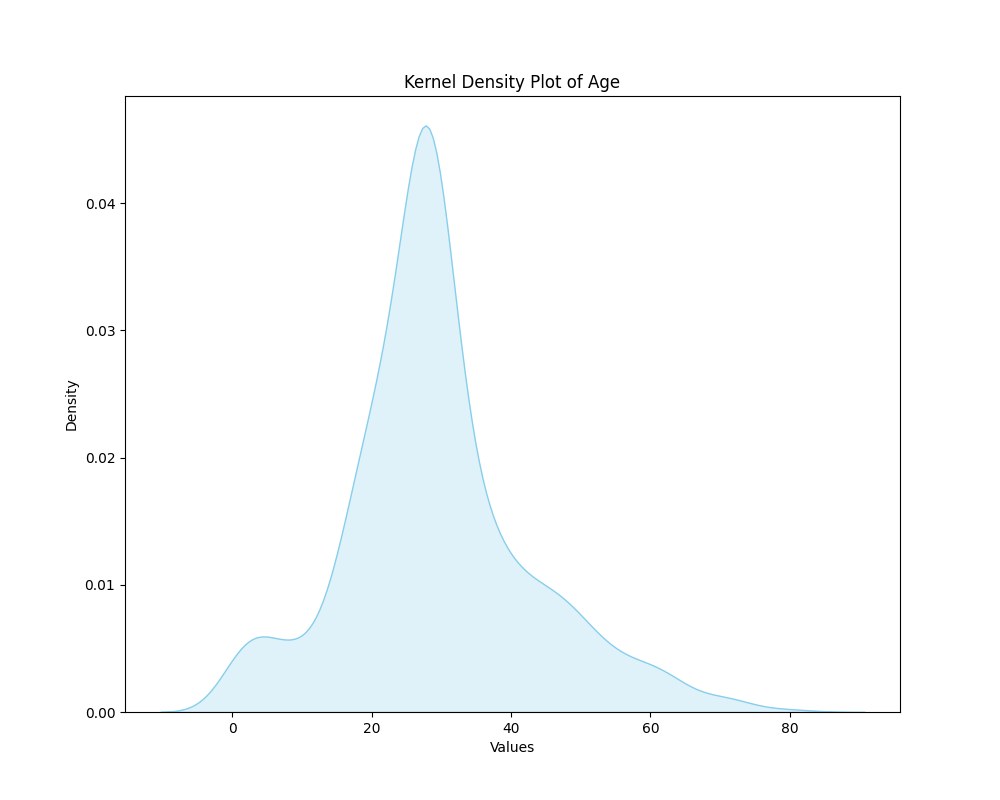
1.2 特征核密度图 (Kernel Density Estimation, KDE)
核密度估计(Kernel Density Estimation,简称KDE)是一种用于估计概率密度函数的非参数方法。它通过在每个数据点周围放置一个核(通常是正态分布的核),然后将这些核叠加起来,形成平滑的估计概率密度函数。
目前我们选择的是特征贡献度最大的高级特征或者原始特征进行核密度估计。
核密度估计图可以帮助你了解单个变量的分布情况,包括峰值和分布的形状。可以从以下二个方面进行对数据的分析。
�� (1)峰值(Peak): 峰值表示概率密度估计图中最高点的高度。
-
在KDE中,峰值越高,表示在该位置的数据点密度越大,即该位置附近的数据点更为集中。
-
峰值的高度并不直接给出概率值,但可以用于比较不同位置的数据密度。
(2)整体形状: 概率密度估计图的整体形状反映了数据分布的趋势。
-
图形的平滑性和波动性可用于判断数据的变异性。
-
平坦的KDE图表明数据相对均匀地分布,而具有峰值和波动的图形可能表示数据在某些区域更为密集。
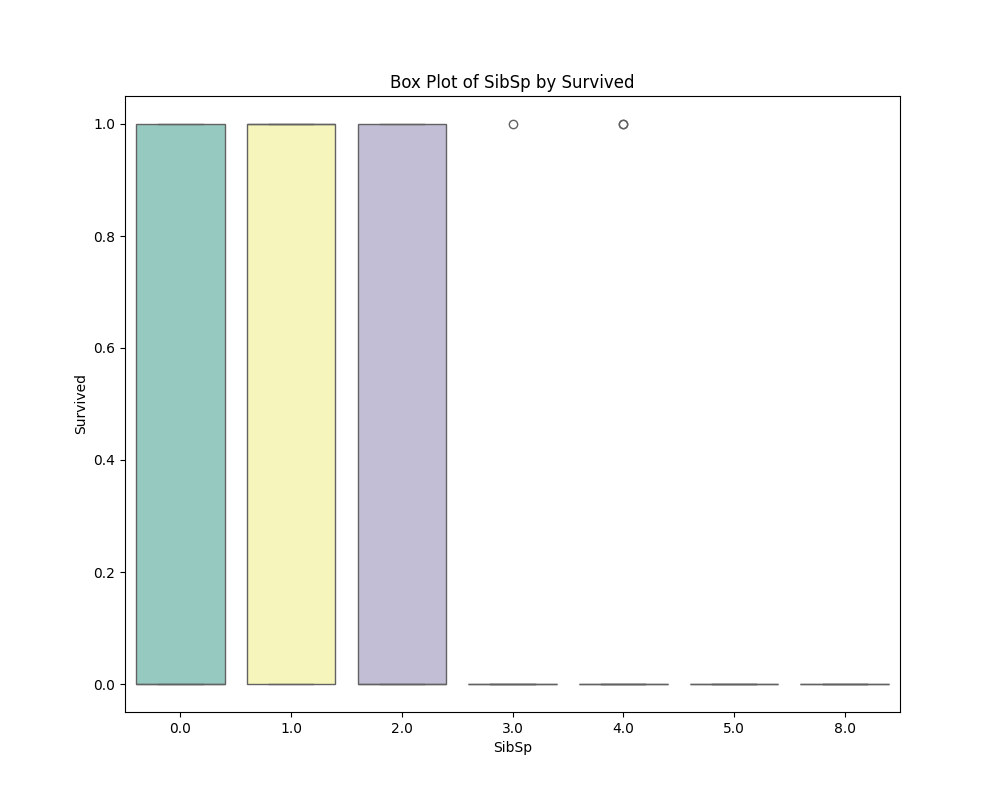
1.3 箱线图 (Box Plot)
箱线图是一种用于可视化数据分布和离群值的有效工具。目前我们选择的是特征贡献度最大的高级特征或者原始特征进行箱线图的绘制。
在分析箱线图时,你可以关注以下几个关键的要素:
(1)箱体(Box): 箱体显示了数据的四分位数范围,即数据的中间50%。
- 箱体的底部和顶部分别表示第1四分位数(Q1,下四分位数)和第3四分位数(Q3,上四分位数),而箱体内部的线表示中位数(Q2)。
(2)须(Whiskers): 须延伸从箱体的两端,表示数据的最大值和最小值,但不考虑异常值。
- 须的长度通常基于数据的分布,具体的计算方式可能有所不同。
(3)异常值(Outliers): 在箱线图中,通常将超出须的1.5倍四分位距的数据点定义为异常值,并用点表示。
- 异常值可能是数据集中的离群值。
(4)整体形状: 观察箱线图的整体形状可以提供关于数据分布的信息。
- 例如,箱体的长度和位置,须的延伸情况,以及异常值的分布等。
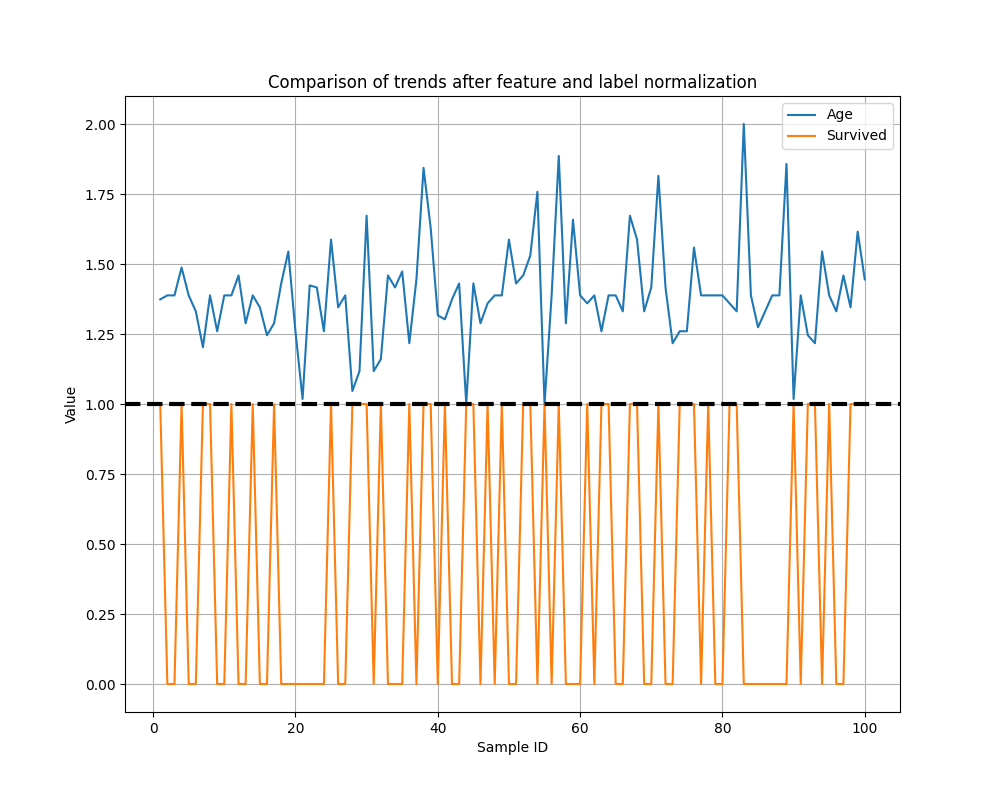
1.4 特征和标签的特征曲线图
查看特征和标签的趋势变化是否一致有助于构建更有效、解释性更强、泛化性能更好的机器学习模型。
目前我们选择的是特征贡献度最大的高级特征或者原始特征进行曲线绘制的,并选取前100个样本显示。
为了方便比较,我们将特征归一化到[1, 2]之间,把标签归一化到[0, 1]之间。
2.训练后的特征分析
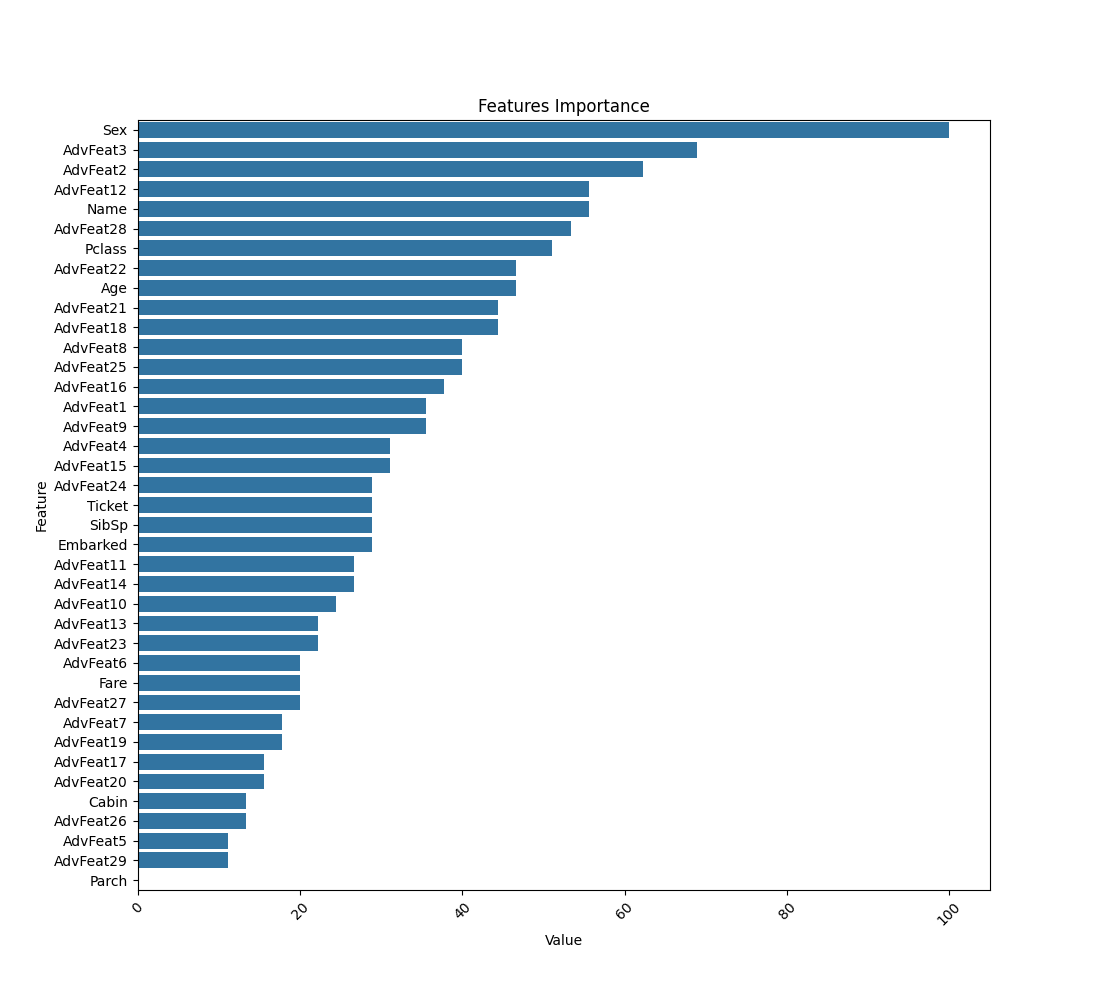
2.1 特征重要性
每个特征对于树模型提供的贡献程度,以下是常见树模型的特征重要性分数的简介。
(1)LightGBM:
LightGBM使用基于树的学习算法,特征重要性主要基于分裂增益(Split Gain)。
(2)CatBoost:
CatBoost也是基于树的学习算法,其特征重要性计算方式与LightGBM相似,主要基于分裂增益。
(3)XGBoost:
XGBoost通过计算特征的增益(Gain)来评估特征的重要性。XGBoost还提供了一种基于覆盖度(Coverage)的特征重要性计算方式,覆盖度表示每个特征在树中的使用频率。
(4)随机森林:
随机森林使用基尼不纯度(Gini impurity)或信息增益(Information Gain)等指标来选择最佳的分裂特征。这些次数的总和或者平均值可以用于衡量特征的重要性。
(5)极限树(Extra Trees):
极限树是随机森林的一种变体,它在节点分裂时使用了更多的随机性。特征重要性的计算方式与随机森林类似。
树模型在分裂的时候,可能会多次用到同一个特征,其特征重要性是这几个节点加权平均�,不同模型的策略不同。
3. 如何数据分析
机器学习的一般人工构建流程如下:
(1)数据分析,了解数据的分布情况,例如:
-
查看是否有冗余:一般情况下,如果热力图中特征之间的相关系数绝对值大于0.8,就应该慎重考虑特征选择。
-
查看特征和标签的相关性:一般情况下,如果热力图中特征和标签之间的相关系数越高特征重要性可能越高。
-
查看特征的概率密度分布:判断数据是否密集,密集可能导致区分度很小。
-
其他方法
(2)特征工程
通过第一步的数据分析进行特征的生成,例如:特征A和特征B相关度很低,那么将特征A和特征B简单的组合(比如:加减乘除)得到特征C,那么特征C可能对于模型的帮助会很大。
举一个简单的例子,例如:我们评测身体的肥胖程度。我们有身高,体重这两个特征,通过特征组合发现了这样一个特征:。
这个特征对于分类有重大的贡献,那这就是BMI,给他赋予身体质量指数的物理含义,用于衡量人体肥胖程度。
(3)模型调优
模型调优主要分为两部分:选择最合适的模型和选择最优的模型参数。
特征工程和模型调优一般是一起的,可以简单理解,不同的数据集,那么就应该对应�不同的最优模型。那这两个步骤将需要花费大量的时间和精力去实现。
使用ChangTianML的数据分析:
(1)您已经得到了有效的特征生成组合,那么可以反向推理新特征的物理含义,例如:以BMI为例(),那我们可以解释:为了考虑不同身高的肥胖程度我们采用了除法,平方项的引入使得该指标对于身高的变化更为敏感,从而更好地反映体重相对于身高的比例。
(2)如果需要更加详尽的数据详情,那么可以使用ChangTianML工具进行分析。
二、模型可视化
模型可视化目前只支持LightGBM,如果最终模型不是LightGBM,那么可能没有生成这部分的图片。
其他模型的可视化正开发中,敬请期待!
1. 树模型的结构可视化
树模型可视化的重要性:
(1)树模型作为一种可解释的模型,你可以清晰地看到每个决策节点的分裂条件以及叶子节点的预测结果。这有助于理解模型是如何基于输入特征进行预测的,使得模型的工作过程更加透明和可解释。
(2)可以了解特征对于预测结果的影响,例如特征A在某个阈值下是否把数据分到正确的类别中了。
(3)可视化树模型有助于向非专业人员、利益相关者或团队成员解释模型的工作原理。
下面介绍多种树模型的显示方式。
树模型图的解释
- 选择特征,特征会根据阈值进行分裂,左边是小于等于阈值,右边则反之。
- 如果分裂的样本中得到较好的结果,则停止分裂,反之继续选择特征分裂。
- 重复步骤上面两个步骤直到所有样本都被分配完成。
树模型的竖向展开图

树模型的横向展开图

树模型的简化展开图

树模型的浅层展开图

2. 决策树的预测路径
决策树的预测路径可以具象化看到模型是如何判断某个样本属于哪个类别的过程。
决策树的全部预测路径
预测路径已用橙色的框标示出来,随机抽一个测试集的样本并在下方列出样本的具体信息。

决策树的预测路径简化

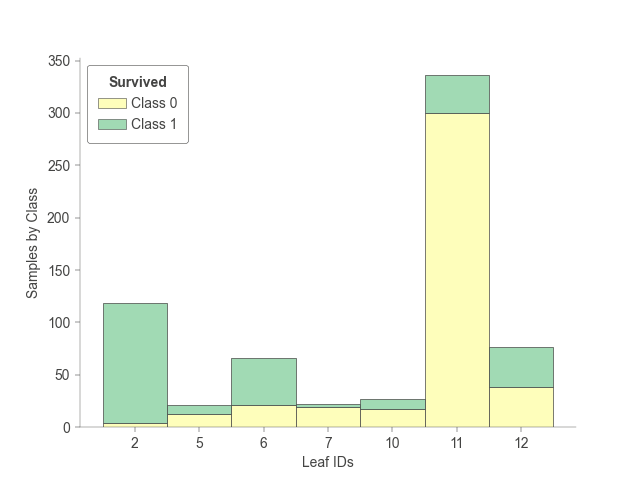
3. 树叶子节点样本树的统计
树模型的各个叶子节点训练的时候包含了多少样本的统计。
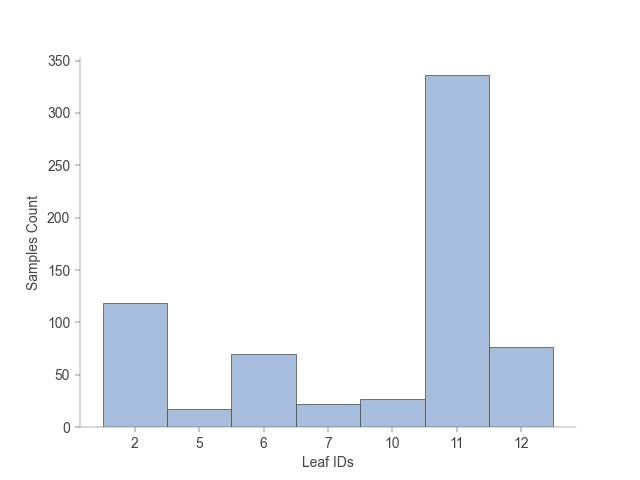
树模型的各个叶子节点训练的时候包含了多少样本的统计,以及每个叶子节点有多少属于各个类别。
三、验证集指标
ROC曲线和混淆矩阵目前只支持输出类别小于等于5种的分类任务。
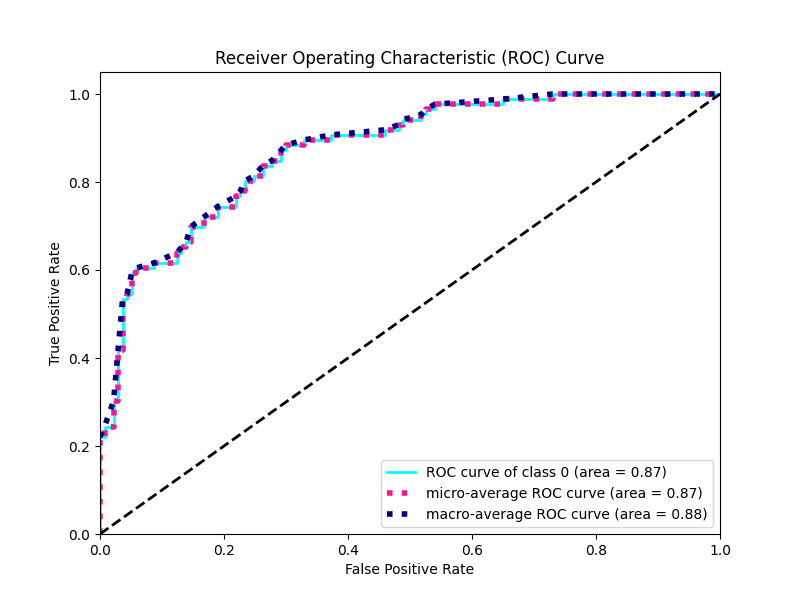
1. ROC曲线
ROC曲线(Receiver Operating Characteristic Curve)是一种用于评估分类器性能的图形工具。主要关注两个�重要的性能指标:True Positive Rate (TPR) 和 False Positive Rate (FPR)。
True Positive Rate (敏感度或召回率):TPR表示在所有实际正例中,模型成功识别为正例的比例。在ROC曲线上,TPR对应纵轴,范围从0到1。
False Positive Rate (假正例率): FPR表示在所有实际负例中,模型错误识别为正例的比例。在ROC曲线上,FPR对应横轴,范围同样从0到1。
意义和用途:
- 模型比较: ROC曲线提供了一种比较不同模型性能的可视化工具。曲线下的面积(AUC)用于量化不同模型在整个ROC空间下的性能,AUC越大,表示模型性能越好。
- 阈值选择: ROC曲线可以帮助选择分类阈值。不同应用场景可能对False Positive Rate和True Positive Rate有不同的关注程度,通过调整分类阈值,可以在这两者之间找到平衡。
- 诊断性能: ROC曲线能够展示模型在不同工作点下的性能,从而帮助你理解模型的诊断性能,特别是在二分类问题中。
- 不受类别不平衡影响: ROC曲线对于类别不平衡的问题更为鲁棒,因为它是基于真正例率和假正例率的比例关系。
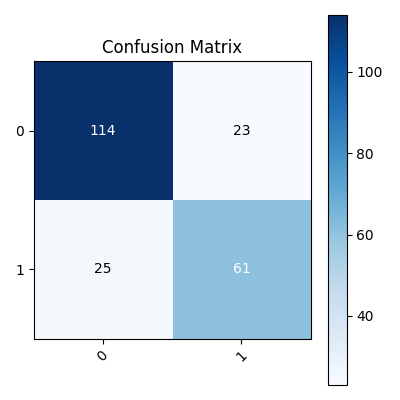
2. 混淆矩阵
验证集指标(Accuracy, Recall, Precision, F1)可以在ChangTianML任务的日志的AutoML得到。
- 真正例(True Positives,TP): 模型正确地将正例样本预测为正例。
- 真负例(True Negatives,TN): 模型正确地将负例样本预测为负例。
- 假正例(False Positives,FP): 模型将负例样本错误地预测为正例。
- 假负例(False Negatives,FN): 模型将正例样本错误地预测为负例。
混淆矩阵的意义和用途:
- 性能评估: 混淆矩阵提供了一个全面的性能评估,可以直观地了解模型在不同类别上的预测准确性。
- 精确度(Accuracy)计算: 精确度是分类器正确预测的总样本数占总样本数的比例,可以通过混淆矩阵计算。,该任务的准确率为: 0.7847533632286996。
- 召回率(Recall)计算: 召回率(也称为敏感度或真正例率)表示模型正确识别的正例样本在所有实际正例样本中的比例。,该任务的召回率为: 0.7847533632286996。
- 精确度(Precision)计算: 精确度表示模型预测为正例的样本中,实际为正例的比例。,该任务的精确率为: 0.7839107317605237。
- F1分数计算: F1分数是精确度和召回率的调和平均,用于综合考虑模型的准确性和全面性。,该任务的f1为: 0.7842670856605463。
附录-1:高级特征与特征贡献度对应表
模型在可视化的时候捆绑特征可能看不清楚,可以通过下表查询相应的高级特征以及特征贡献度。
| 特征编号 | 高级特征 | 特征贡献度 |
|---|---|---|
| 35.55555555555556 | ||
| 62.22222222222222 | ||
| 68.88888888888889 | ||
| 31.11111111111111 | ||
| 11.11111111111111 | ||
| 20.0 | ||
| 17.77777777777778 | ||
| 40.0 | ||
| 35.55555555555556 | ||
| 24.444444444444443 | ||
| 26.666666666666668 | ||
| 55.55555555555556 | ||
| 22.22222222222222 | ||
| 26.666666666666668 | ||
| 31.11111111111111 | ||
| 37.77777777777778 | ||
| 15.555555555555555 | ||
| 44.44444444444444 | ||
| 17.77777777777778 | ||
| 15.55555555555555 | ||
| 44.44444444444444 | ||
| 46.666666666666664 | ||
| 22.22222222222222 | ||
| 28.888888888888886 | ||
| 40.0 | ||
| 13.333333333333334 | ||
| 20.0 | ||
| 53.333333333333336 | ||
| 11.11111111111111 |